什么是聚类分析?
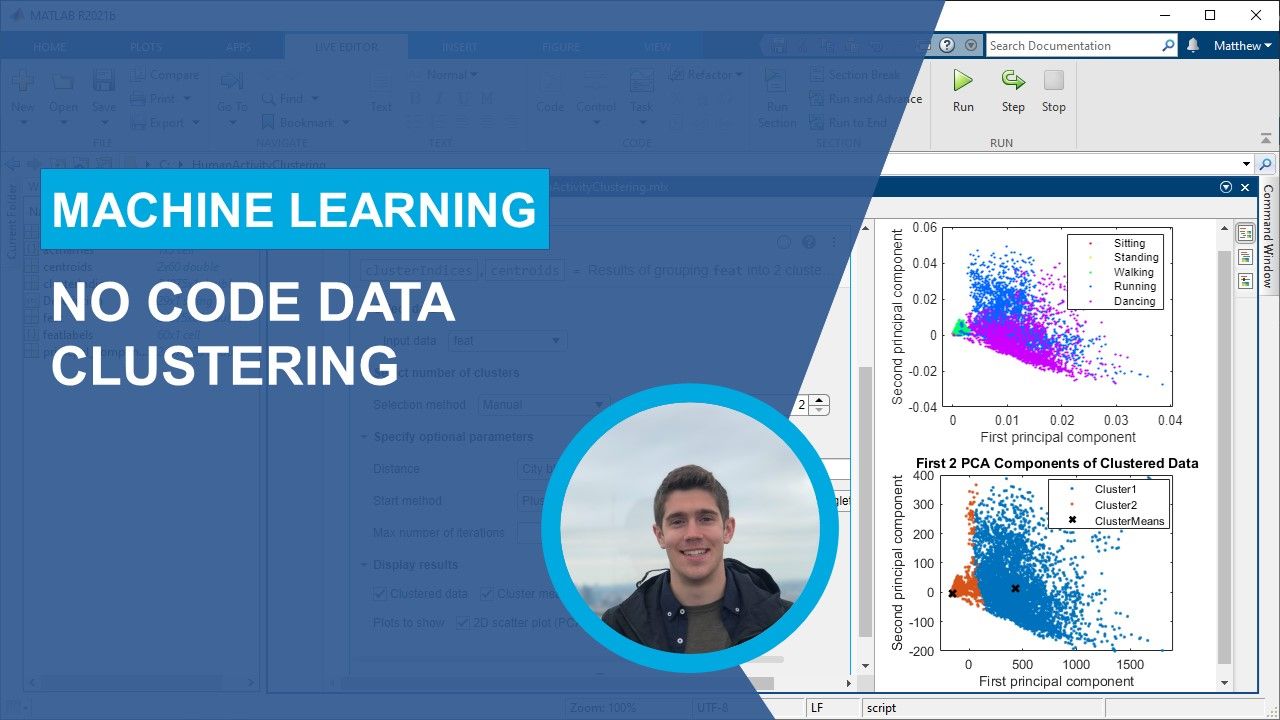
聚类分析包括应用一个或多个聚类算法,目标是在数据集中寻找隐藏的模式或分组。聚类算法构成分组或聚类,与任何其他聚类中的数据相比,聚类中的数据具有更高的相似度。聚类建模的相似度衡量可以通过 Euclidean 距离、概率距离或其他指标进行定义。
聚类分析是不受监督的学习方法,也是探索性数据分析中的重要任务。常用的聚类算法包括:
- 分层聚类分析:通过创建聚类树构建多级聚类层次
- k 均值聚类分析:基于到聚类形心的距离将数据划分为 k 相异聚类
- 高斯混合模型:将聚类作为多元正态密度成分的混合建模
- 自组形态分析法:使用学习拓扑和数据分布的神经网络
各个算法的区分特征是衡量相似度的指标。
可在用于序列分析和遗传聚类的生物信息学;用于顺序和模式挖掘的数据挖掘;用于图像分割的医疗成像以及用于对象识别的计算机视觉中使用聚类分析。
有关聚类分析算法的更多详情,请参阅 Statistics and Machine Learning Toolbox 和 Deep Learning Toolbox。
示例与具体方法
软件参考
另请参阅: Statistics and Machine Learning Toolbox, Deep Learning Toolbox, 机器学习, 不受监督的学习, adaboost, 数据分析, 数学建模, 人工智能 (AI), 概率分布

您也可以从以下列表中选择网站:
美洲
- América Latina (Español)
- Canada (English)
- United States (English)
欧洲
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
亚太
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)